In this post, we will delve into the YOLO (You Only Look Once) models [1], which have revolutionised the field of object detection with their speed and accuracy. We will start by discussing the traditional methods used for object detection, highlighting their limitations and the challenges they pose. Following this, we will introduce the YOLO models, explaining their unique architecture and the advantages they offer over traditional methods.
We will then trace the evolution of YOLO models from their inception to the latest versions, YOLOv8 and YOLOv9. This section will cover the key innovations and improvements introduced in each version, demonstrating how YOLO has maintained its cutting-edge status in object detection.
Finally, we will provide a detailed look at the architecture and functionalities of YOLOv8 and YOLOv9, showcasing how these models push the boundaries of what is possible in real-time object detection. By the end of this post, you will have a comprehensive understanding of the YOLO models, their evolution, and why they are preferred for various object detection tasks.
In future posts, we will explore specific applications of YOLO models, such as detecting nodes, edges, and arrows in human-written mind maps. But for now, let’s focus on understanding the power and versatility of YOLO models in the realm of object detection.
What is Object Detection?
Object detection is a crucial task in computer vision that involves identifying and locating multiple objects within an image. Unlike image classification, which assigns a single label to an entire image, object detection provides both the class labels and positions of objects. This is achieved through bounding boxes, which are rectangular borders drawn around each detected object. Object detection is widely used in applications such as autonomous driving, surveillance, and image analysis, due to its ability to provide detailed information about the presence and location of objects within a scene.
Traditional Methods and Tools for Object Detection
Before the advent of deep learning, object detection relied heavily on handcrafted features and traditional machine learning algorithms. These methods, while effective to some extent, often involved complex pipelines and had limitations in terms of speed and accuracy. Let’s explore some of the main traditional approaches in the field of computer vision:
Commonly Used Libraries
OpenCV (cv2): OpenCV, short for Open Source Computer Vision Library, is an open-source computer vision and machine learning software library. It was originally developed by Intel in 1999, and its primary developers included Gary Bradski and Adrian Kaehler [2]. OpenCV is written in C and C++, and it has bindings for various programming languages, including Python, Java, and MATLAB. The library provides a wide range of tools for image processing, feature extraction, and object detection. It supports traditional methods like edge detection, corner detection, contour detection, morphological operations, and template matching. OpenCV has been a cornerstone in computer vision applications, offering extensive functionality and being widely used for both academic and industrial purposes.
Feature Descriptors
Feature descriptors were widely used for object detection before the deep learning era. They identify and describe local features in images that are invariant to transformations such as scale, rotation, and translation.
- SIFT (Scale-Invariant Feature Transform): SIFT, introduced by David Lowe in 1999, detects and describes local features in images [3]. It is highly robust and invariant to scale, rotation, and translation, making it effective for object detection and matching. However, SIFT is computationally expensive.
- SURF (Speeded-Up Robust Features): SURF was introduced by Herbert Bay et al. in 2006 as an improvement over SIFT [4]. It offers faster computation while maintaining similar robustness and accuracy. SURF uses integral images and approximates the Hessian matrix to detect key points and generate descriptors.
- BRIEF (Binary Robust Independent Elementary Features): BRIEF was introduced by Michael Calonder et al. in 2010 as a faster alternative to SIFT and SURF [5]. It uses binary strings as descriptors, making it less computationally intensive but not invariant to rotation.
Edge Detection
Edge detection is a fundamental technique used in image processing to identify the boundaries of objects within images. It detects regions in an image where the intensity of pixels changes sharply.
- Techniques: Common edge detection methods include the Canny edge detector, Sobel operator, and Prewitt operator. The Canny edge detector, introduced by John Canny in 1986, is particularly notable for its ability to detect a wide range of edges in images with low error rates [6].
- Applications: Edge detection is used as a preprocessing step in various computer vision tasks, including object detection, recognition, and image segmentation.
- Code Example: from OpenCV Canny Edge Detection Tutorial


Corner Detection
Corner detection identifies points in an image where the gradient changes sharply in multiple directions, which often corresponds to the corners of objects. These points are useful for matching, tracking, and recognising objects.
- Techniques: The Harris corner detector, introduced by Chris Harris and Mike Stephens in 1988, is a widely used method [7]. The Shi-Tomasi corner detection, introduced in 1994, improves on Harris by selecting the strongest corners [8].
- Applications: Corner detection is utilised in object detection, image stitching, and motion tracking.
Contour Detection
Contour detection identifies the outlines of objects within an image. Contours are curves that join continuous points along a boundary that have the same intensity.
- Techniques: The findContours function in OpenCV is commonly used to detect contours after applying edge detection or thresholding. Contour detection is critical for shape analysis and object recognition [9].
- Applications: Contour detection is used in shape analysis, object detection, and recognition.
- Code Example: from OpenCV Contour Detection Tutorial.


Morphological Operations
Morphological operations process images based on their shapes. These operations apply a structuring element to an input image and are useful for removing noise and detecting object boundaries.
- Techniques: Common operations include erosion, dilation, opening, and closing. Erosion removes pixels on object boundaries, while dilation adds pixels to object boundaries [10].
- Applications: Morphological operations are used in preprocessing steps to enhance object detection by cleaning up binary images.
Threshold Segmentation
Threshold segmentation is a simple but effective technique used to separate objects from the background in an image based on pixel intensity.
- Techniques: The process involves converting an image to grayscale and then applying a threshold to create a binary image. Pixels above the threshold are set to one value (e.g., white), and pixels below the threshold are set to another value (e.g., black) [11].
- Applications: Threshold segmentation is widely used in applications such as document image analysis, medical imaging, and object detection.
Limitations of Traditional Methods
- Complexity: Traditional methods often involve multiple stages, including feature extraction, region proposal, and classification, making the pipeline complex and computationally expensive.
- Performance: These methods struggle with real-time performance and often lack robustness in handling variations in object size, orientation, and occlusion.
- Accuracy: Handcrafted features may not capture the intricate details of objects as effectively as learned features from deep learning models, leading to lower detection accuracy in complex scenes.
Traditional object detection methods paved the way for advancements in the field, but they have been largely surpassed by modern deep learning techniques like YOLO, which offer superior performance in terms of both speed and accuracy.
Introduction to YOLO Models
YOLO models [1] have revolutionised the field of object detection with their speed and accuracy. Unlike traditional methods, which often involve complex pipelines and multiple stages, YOLO frames object detection as a single regression problem, straight from image pixels to bounding box coordinates and class probabilities. This section will introduce the YOLO models, their architecture, the advantages they offer over traditional methods, and their evolution over time.
YOLO Model Architecture
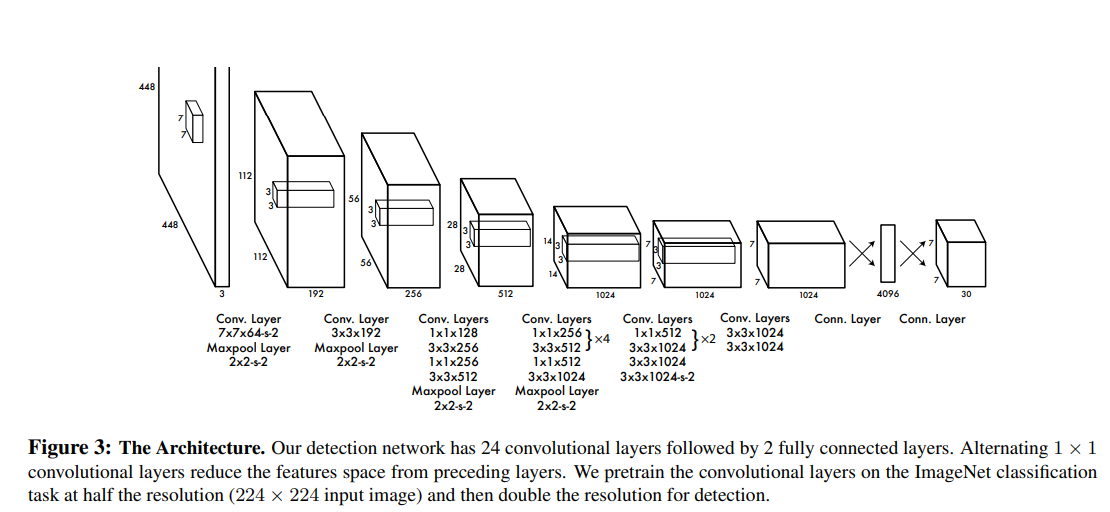
The YOLO model architecture is based on a single neural network [1] that processes the entire image in one forward pass, making predictions for multiple bounding boxes and their class probabilities simultaneously. Here’s a breakdown of the architecture:
- Input Image: The input image is divided into an SxS grid. Each grid cell is responsible for predicting B bounding boxes and C class probabilities.
- Convolutional Layers: YOLO uses a series of convolutional layers to extract features from the input image. These layers help the model learn spatial hierarchies and detect objects at different scales.
- Fully Connected Layers: After the convolutional layers, the features are flattened and passed through fully connected layers, which predict the bounding box coordinates, confidence scores, and class probabilities for each grid cell.
- Output: The final output is a tensor of shape SxSx(Bx5+C), where each cell contains B bounding boxes (each with 5 parameters: x, y, w, h, confidence) and C class probabilities.
Differences Between Traditional Approaches and YOLO
Traditional Approaches:
- Pipeline Complexity: Traditional methods often involve multiple stages such as feature extraction, region proposal, and classification.
- Feature Descriptors: Rely on handcrafted features like SIFT, SURF, and HOG.
- Region Proposal: Use algorithms like Selective Search to propose regions of interest, which are then classified by a separate model.
- Speed: Typically slower due to the multi-stage pipeline and computational complexity.
YOLO Approach:
- Unified Model: YOLO frames object detection as a single regression problem, using a single neural network to predict bounding boxes and class probabilities directly from full images in one evaluation.
- End-to-End Training: Trains the entire model end-to-end, optimising for both bounding box prediction and class probabilities simultaneously.
- Speed: Extremely fast, capable of processing images in real-time (up to 45 frames per second for the original YOLO model).
- Accuracy: Despite its speed, YOLO achieves high accuracy and can effectively handle a wide range of object scales and aspect ratios.
Advantages of YOLO
- Speed: YOLO is incredibly fast, making it suitable for real-time applications such as autonomous driving and surveillance.
- Simplicity: A single network predicts both bounding boxes and class probabilities, simplifying the detection pipeline.
- Global Context: YOLO reasons globally about the image, allowing it to detect multiple objects and their relationships effectively.
- Accuracy: Achieves high accuracy on standard benchmarks, making it a reliable choice for various object detection tasks.
Evolution of YOLO Models
The YOLO family has evolved significantly since its inception, with each version introducing key improvements in architecture, speed, and accuracy.
YOLOv1:
- Introduction: The original YOLO model was introduced by Joseph Redmon et al. in 2016 [1]. It framed object detection as a single regression problem and achieved 45 frames per second (fps) on PASCAL VOC.
- Key Innovations: Simplified the detection pipeline by predicting bounding boxes and class probabilities directly from full images.
YOLOv2 (YOLO9000):
- Introduction: YOLOv2, also known as YOLO9000, was introduced to improve both speed and accuracy [12]. It was trained on both the COCO dataset and ImageNet classification dataset simultaneously.
- Key Innovations: Introduced batch normalisation, high-resolution classifier, and anchor boxes.
YOLOv3:
- Introduction: YOLOv3 further refined the model with better performance on small objects and improved multi-scale predictions [13].
- Key Innovations: Used Darknet-53 backbone, multi-scale predictions, and binary cross-entropy loss for class predictions.
YOLOv4:
- Introduction: YOLOv4, introduced by Alexey Bochkovskiy et al., brought significant improvements in both architecture and training strategies [14].
- Key Innovations: Used CSPDarknet53 backbone, PANet for path aggregation, and various training tricks for improved performance.
YOLOv8:
- Introduction: YOLOv8 [15] marked a significant leap in the YOLO series, incorporating modern architectural elements and training techniques to push the boundaries of object detection performance.
- Key Innovations: Combined CSPDarknet53, FPN, and PAN for better feature aggregation, and improved labelling tools.
YOLOv9:
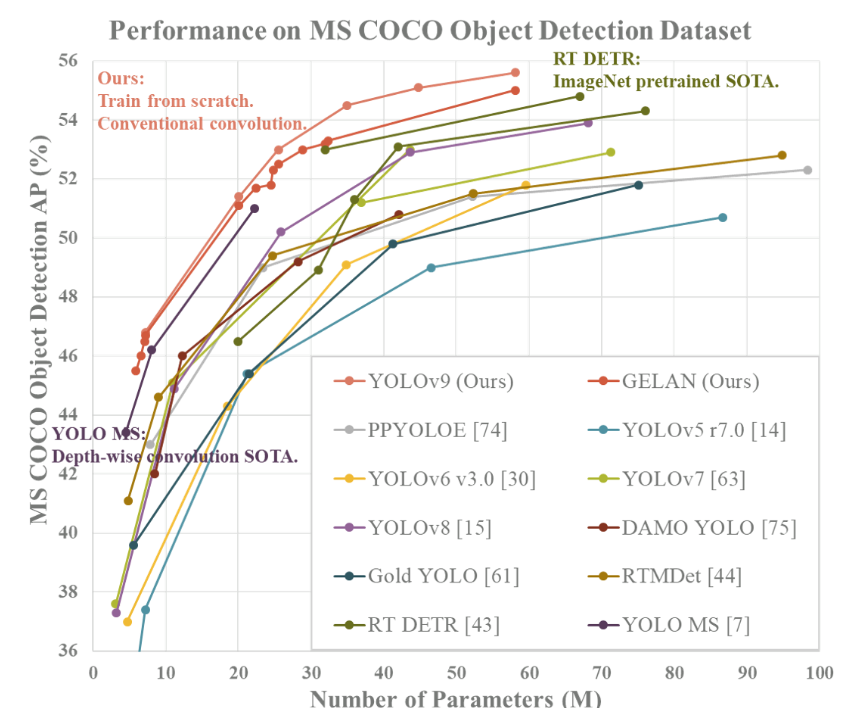
- Introduction: YOLOv9 represents the latest advancement in the YOLO family, focusing on optimising both speed and accuracy to deliver state-of-the-art results [16].
- Key Innovations: Further refinements in neural network architecture, higher mAP, and faster inference.
Conclusion
In this post, we explored the YOLO (You Only Look Once) models, which have significantly advanced the field of object detection with their innovative approach. We started by discussing traditional methods for object detection and their limitations. We then introduced the YOLO models, detailing their unique architecture, advantages, and the evolution from YOLOv1 to the latest YOLOv9.
YOLO models have transformed object detection by framing it as a single regression problem, resulting in unparalleled speed and accuracy. They simplify the detection pipeline by predicting bounding boxes and class probabilities directly from full images in a single pass. This efficiency makes YOLO models ideal for real-time applications in various domains, from autonomous driving to surveillance.
In the next post, we will delve into a real application case study where we will use YOLOv9 to recognise human-written mind maps. This will include detecting nodes, edges, and end tips to distinguish between arrows and lines. We will discuss the training process, dataset preparation, and evaluate the performance of the model in this specific application. Stay tuned for an in-depth exploration of how YOLOv9 can be applied to complex, real-world tasks involving handwritten documents.
References
[1] Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You Only Look Once: Unified, Real-Time Object Detection.
[2] Bradski, G., “The OpenCV Library,” Dr. Dobb’s Journal of Software Tools (2000).
[3] Lowe, D.G., “Object Recognition from Local Scale-Invariant Features,” Proceedings of the International Conference on Computer Vision (1999).
[4] Bay, H., Tuytelaars, T., & Van Gool, L., “SURF: Speeded Up Robust Features,” European Conference on Computer Vision (2006).
[5] Calonder, M., Lepetit, V., Strecha, C., & Fua, P., “BRIEF: Binary Robust Independent Elementary Features,” European Conference on Computer Vision (2010).
[6] Canny, J., “A Computational Approach to Edge Detection,” IEEE Transactions on Pattern Analysis and Machine Intelligence (1986).
[7] Harris, C., & Stephens, M., “A Combined Corner and Edge Detector,” Alvey Vision Conference (1988).
[8] Shi, J., & Tomasi, C., “Good Features to Track,” IEEE Conference on Computer Vision and Pattern Recognition (1994).
[9] Suzuki, S., & Abe, K., “Topological Structural Analysis of Digitized Binary Images by Border Following,” Computer Vision, Graphics, and Image Processing (1985).
[10] Haralick, R.M., Sternberg, S.R., & Zhuang, X., “Image Analysis Using Mathematical Morphology,” IEEE Transactions on Pattern Analysis and Machine Intelligence (1987).
[11] Otsu, N., “A Threshold Selection Method from Gray-Level Histograms,” IEEE Transactions on Systems, Man, and Cybernetics (1979).
[12] Redmon, J., & Farhadi, A. (2016). “YOLO9000: Better, Faster, Stronger.”
[13] Redmon, J., & Farhadi, A. (2018). “YOLOv3: An Incremental Improvement.”
[14] Bochkovskiy, A., Wang, C.-Y., & Liao, H.-Y. M. (2020). “YOLOv4: Optimal Speed and Accuracy of Object Detection.”
[15] Reis, D., Kupec, J., Hong, J., & Daoudi, A. (2024). “Real-Time Flying Object Detection with YOLOv8.”
[16] Wang, C.-Y., Yeh, I.-H., & Liao, H.-Y. M. (2024). “YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information.”


