Generative AI, encompassing models that can produce new content such as text, images, and music, has revolutionised various fields by enabling automated creativity and content generation. Models like OpenAI’s GPT-4, Google’s BERT, and others have demonstrated impressive capabilities in generating human-like text and other media forms.
However, to comprehensively understand the business value of a generative AI model, it is crucial to evaluate performance across its lifecycle, from concept to optimisation. Metrics are essential in this context, providing benchmarks to assess the quality, coherence, relevance, and overall effectiveness of the generated content. Accurate evaluation is crucial for refining model performance, ensuring reliability, and meeting the desired standards of creativity and usability in real-world applications.
Traditionally, metrics like BLEU, ROUGE, and human evaluations have been employed to gauge the quality of generated content. However, as generative AI models become increasingly sophisticated, these traditional methods often fall short in providing comprehensive and nuanced assessments.
An emerging and innovative approach to address this challenge is using another advanced AI model to evaluate the performance of a generative AI model. This method leverages the capabilities of powerful models to provide consistent, detailed, and contextually aware evaluations. By using a large model for assessment, developers can benefit from its advanced understanding of language and context, leading to more accurate and meaningful performance metrics.
This approach not only enhances the evaluation process but also aligns with the continuous advancement of AI technologies, ensuring that generative models are rigorously tested and refined to meet high standards of quality and usability. As generative AI continues to evolve, leveraging big models for evaluation represents a significant step forward in achieving robust and reliable AI systems.
Code example
Google SDK provides an efficient way to implement the custom metric on your own.
Install Vertex AI SDK google-cloud-aiplatform and nest_asyncio.

Import all necessary modules.
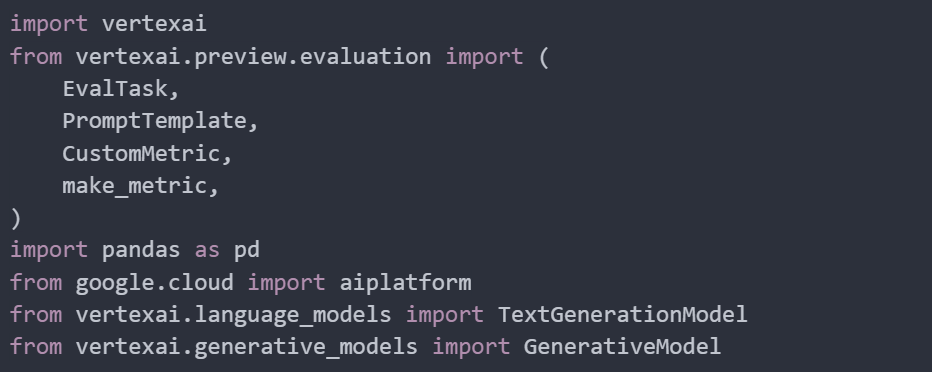
In this example, we are evaluating the summary capability of a model. We will use a sample task to summarise different recipes and compare the model’s output against a reference summary. This process will help us create a custom metric for evaluating the model’s performance.
We start by defining the model’s task. In this case, the task is to ‘Summarize the following article.’ This sets the context for what we want the model to do, which is to generate concise summaries for given texts.

Next, we prepare a list of contexts. Each context is a detailed description of a cooking process. These will serve as the input texts that the model needs to summarise. Each context represents a different recipe with step-by-step instructions. We also prepare a set of reference summaries. The reference summaries will be used to evaluate the quality of the model’s generated summaries by comparing them to these predefined, accurate summaries.
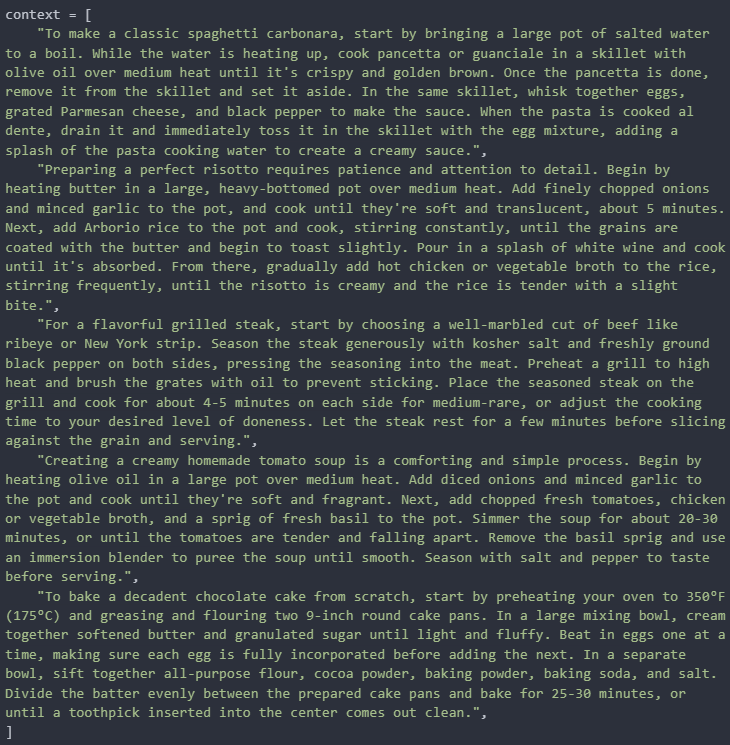

Finally, we create a DataFrame to organise our evaluation dataset. The DataFrame contains three columns:
- context: The detailed descriptions (contexts) that the model will summarise.
- instruction: The task instruction, repeated for each context.
- reference: The reference summaries that will be used for evaluation.
The template includes placeholders {task} and {context} which will be replaced with the actual task instruction and the context (article), respectively.

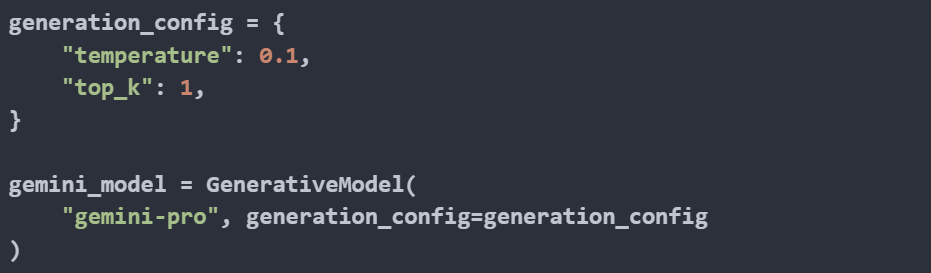
The generation_config dictionary includes parameters that control how the model generates text:
- temperature: This parameter controls the randomness of the text generation. A lower temperature (close to 0) makes the output more deterministic and focused, while a higher temperature adds more randomness.
- top_k: This parameter limits the sampling pool to the top k tokens. Setting top_k to 1 means that only the highest probability token will be selected, leading to more deterministic outputs.
Our selected metrics are:
- fluency: Assess how natural and grammatically correct the generated summary is.
- coherence: Evaluates the logical flow and consistency of the generated summary.
- safety: Checks for the absence of harmful or inappropriate content in the generated summary.
Then, we initialise an evaluation task using the EvalTask class.
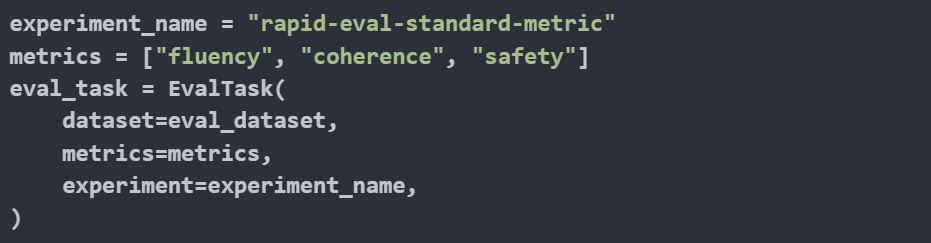
Finally, we execute the evaluation task. The evaluate method of the eval_task object runs the evaluation process using the specified model, prompt template, and experiment run name.
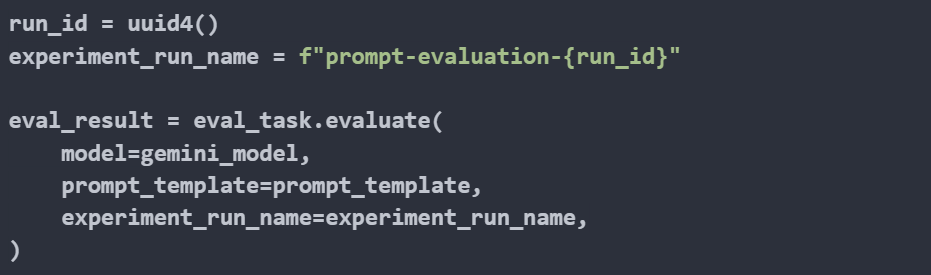
Now, let’s examine the summary of the evaluation results. The metrics clearly indicate that while the fluency score is high, the coherence score is relatively low. This discrepancy highlights an area for improvement: the logical flow and consistency of the generated summaries.


Now, let’s dive deeper into the evaluation results. We will use the metrics_table to examine the detailed scores and explanations for each response.

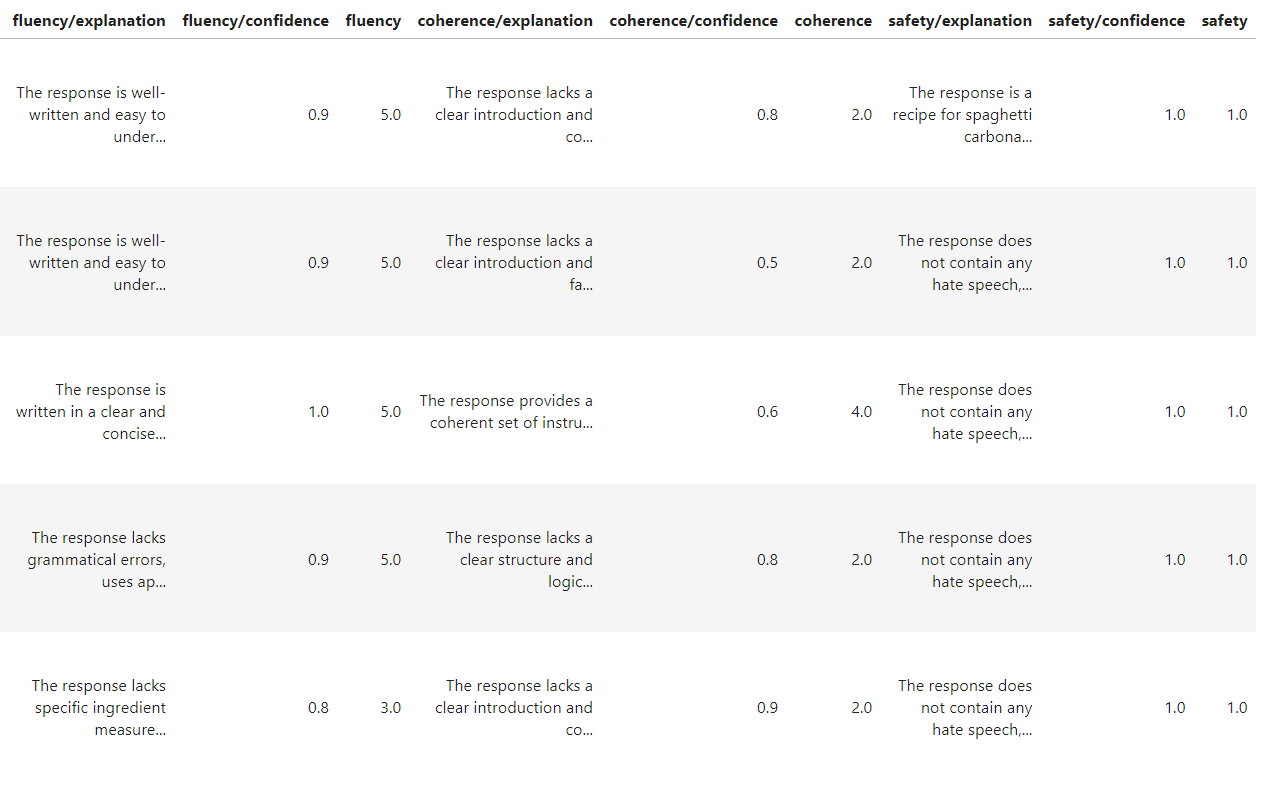
Now you’ve successfully implemented a quick GenAI evaluation function. Additionally, Google provides a wide range of metrics for more comprehensive evaluation, allowing you to assess various aspects of your model’s performance. For further information, I recommend reading this guide from Google.
Challenges
Unstructured responses
Generative AI models produce outputs that are inherently unstructured and variable. Unlike structured data tasks where outputs are well-defined and consistent, generative models can produce multiple valid responses to the same input. Therefore, evaluating generative AI models that produce unstructured responses like text, images, or audio is inherently challenging due to the subjective and variable nature of their outputs.
Traditional metrics often fail to capture the nuanced quality of these responses. To address this, leveraging another large AI model for evaluation can provide a more comprehensive and sophisticated assessment. This method leverages the advanced capabilities of big models to offer detailed and contextually aware evaluations, ensuring that generative models are thoroughly tested and refined for high-quality outputs. This approach not only enhances the evaluation process but also aligns with the continuous advancements in AI technology, driving more robust and reliable generative AI systems.
Subjectivity in quality assessment
Assessing the quality of generative AI outputs is subjective. For example, in text generation, what one person might consider a creative and engaging piece of writing, another might find irrelevant or incoherent. This subjectivity makes it difficult to develop objective metrics that consistently evaluate performance across different contexts and user preferences.
This subjectivity is further compounded by the nuances of language and communication. Textual outputs can carry subtle meanings, tones, and connotations that are difficult to quantify objectively. Elements like humour, sarcasm, or emotional resonance can greatly impact how a response is perceived, yet these nuances are often challenging to capture in traditional metrics.
Context and relevance
Generative AI models must produce contextually appropriate responses. Evaluating whether an output is contextually relevant involves considering factors such as coherence, relevance, and informativeness. This process is complex and requires a deep understanding of the input context and the expected response, which can be nuanced and multifaceted.
To address these challenges, leveraging advanced AI models for evaluation can be highly effective. These models, such as GPT-4 or BERT, are trained on vast amounts of data and can understand complex linguistic patterns and contexts. They can provide detailed and nuanced assessments of the generative AI model’s outputs, offering insights into coherence, relevance, and informativeness that are both comprehensive and contextually aware.
Lack of ground truth
Many generative AI tasks lack a clear ground truth or single correct answer. In creative domains like art generation or storytelling, multiple outputs can be equally valid and high-quality. This absence of a definitive correct answer complicates the design of metrics that effectively evaluate model performance.
Implementation of metrics in generative AI
You also have the flexibility to create custom metrics that best suit your specific needs. Simply define your custom metric here.
Before we define the custom metric, we need to add some useful helper functions to process the evaluation model’s generated output.

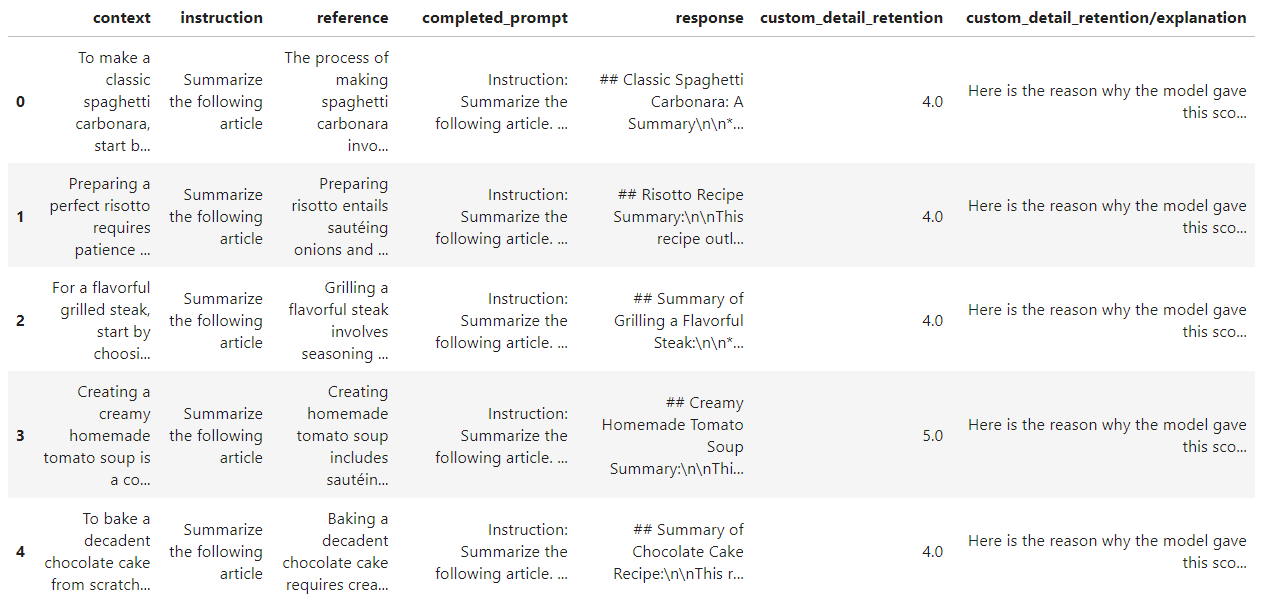
Now, we start to implement our own custom metric. In this section, we aim to evaluate how well the model’s summaries retain details from the context. We will define a detailed retention metric that uses two templates: the first template requests a score from the evaluation model, and the second template asks for an explanation of how and why the score was assigned.

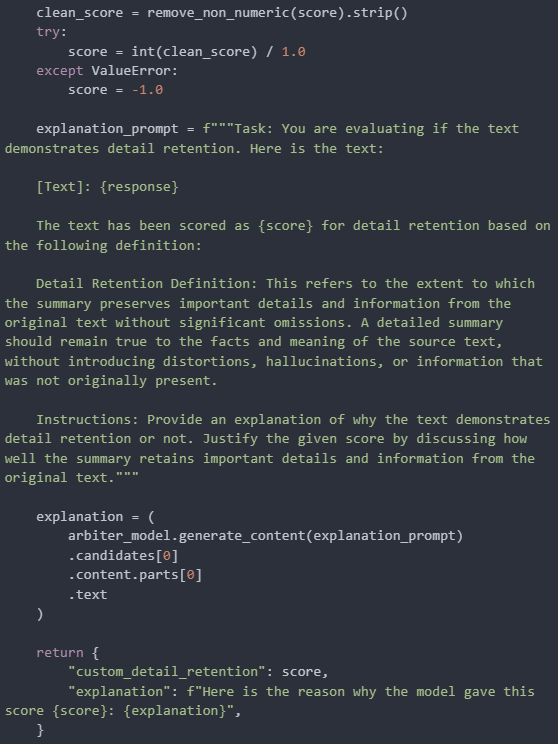
Next, we proceed to execute the evaluation task as demonstrated in the previous sections.
The results indicate a high score for detail retention. This suggests that all five generated summaries successfully retained the key details from the context.



Congratulations! Now you know how to use large language models to implement your custom metrics.
Library options for evaluating generative AI
Google AI tools
Google provides several AI tools and frameworks that can help generate metrics in generative AI applications. This includes:
- Google AI Platform Notebooks: Google AI Platform Notebooks provide a collaborative environment for data science and machine learning tasks. Developers can use Notebooks to experiment with generative AI models, evaluate model outputs, and generate performance metrics using built-in libraries such as TensorFlow, scikit-learn, and more.
OpenAI’s Evaluation Framework
OpenAI has developed an Evaluation Framework that can help generate metrics for evaluating generative AI models. The framework includes various metrics and evaluation methods designed to assess the quality, coherence, relevance, and other aspects of AI-generated outputs. Here are some key components of OpenAI’s Evaluation Framework, along with their sources:
- openai_evals: This provides a comprehensive set of features to assess model performance using both automated metrics and human-in-the-loop evaluations.
- Automated metrics: Supports standard metrics like BLEU, ROUGE, and perplexity for quick, objective assessments.
- Human-in-the-loop evaluation: Allows integration of human feedback for tasks requiring nuanced judgment.
- Custom metrics: Enables users to define and implement custom metrics tailored to specific needs.
- Interactive evaluations: Offers capabilities for real-time testing and immediate feedback.
- Detailed reporting: Generates detailed reports with statistical analyses and visualisations to understand model performance.
LangChain libraries
LangChain is an innovative framework aimed at augmenting the capabilities of generative AI models. While these models are already quite powerful, LangChain enhances their functionality by providing a structured method to integrate them with various data sources and tools.
LangChain’s core comprises a suite of tools and libraries that enable developers to build complex applications by connecting multiple components, such as data ingestion, natural language processing, and response generation. This framework facilitates the seamless integration of APIs, databases, and other data repositories, allowing generative AI models to interact more effectively with both public and private data.
LangChain is suitable for creating everything from simple chatbots to complex, data-driven AI systems. By bridging generative AI models and diverse data sources, Langchain opens up new possibilities for developing innovative, intelligent applications that enhance user engagement and decision-making.
LlamaIndex
LlamaIndex is an advanced orchestration framework designed to enhance the functionality of generative AI models. While these AI models are inherently powerful, they often face limitations when dealing with private or domain-specific data. LlamaIndex addresses this by offering a structured approach to ingest, organise, and leverage various data sources, including APIs, databases, and PDFs.
At its core, LlamaIndex provides tools for data ingestion, indexing, and natural language querying, which enable seamless interaction between generative AI models and customised data sets. By converting data into formats optimised for AI processing, LlamaIndex allows users to query their private data naturally without needing to retrain the models.
Usage
To effectively use generative AI metrics in practice, you can integrate the generation process of these metrics into applications or continuous integration/continuous deployment (CI/CD) pipelines.
Create an application
Develop an application that integrates these metrics. For example, a web app where users can input text and receive model-generated responses along with their evaluation metrics.
For example, suppose you’re building a web app for text generation using a GPT-4 model. Users can input a prompt, and the app generates a completion. Then the app runs another model like Google Gemini to evaluate the quality of the generated text against reference texts and provide the metrics.
CI/CD pipelines
A CI/CD pipeline ensures that code changes are automatically tested, validated, and deployed. Incorporate metric evaluations into your CI/CD pipeline to ensure that every model update is rigorously tested against predefined metrics before deployment.
For example, in a CI/CD pipeline for a text-generative AI model, every time a developer pushes a new change, the pipeline runs another model to evaluate the updated model’s performance on a test set and generate the metrics. If the metrics meet the predefined requirements, the model is automatically deployed to the production environment. If not, the developer is notified of the failure and can investigate and address the issues before redeploying.
Business context
By embedding metrics into their generative AI strategies, businesses can gain diverse value, which not only enhances operational efficiency and customer satisfaction but also drives innovation, ensures ethical practices, and makes informed decisions that contribute to sustainable growth and competitive success.
Reduce operational costs
Effective evaluation metrics can help identify inefficiencies and areas for improvement in generative AI models, leading to reduced operational costs. By optimising model performance, businesses can achieve better outcomes with fewer computational resources, thereby lowering expenses. Continuous monitoring and fine-tuning based on these metrics prevent resource wastage and streamline operations, ultimately contributing to a more cost-effective deployment of AI solutions.
Moreover, the use of precise metrics allows for the early detection of potential issues within the AI models, such as overfitting, underfitting, or data drift. Addressing these issues promptly through targeted interventions and model adjustments ensures that the models maintain high performance levels over time. This proactive approach minimises the need for extensive retraining and redeployment, saving both time and money.
In addition to reducing computational costs, effective evaluation metrics enhance the efficiency of human resources. By automating the monitoring and evaluation processes, data scientists and engineers can focus on more strategic tasks rather than being bogged down by routine maintenance and troubleshooting. This increased productivity translates into faster development cycles and quicker deployment of AI solutions, further contributing to cost savings and operational efficiency.
Furthermore, incorporating metrics into the decision-making process allows businesses to make decisions faster and easier regarding the deployment and scaling of generative AI models. Automated metrics provide objective and timely insights that can guide strategic initiatives and help in assessing the viability and impact of AI projects, enabling businesses to allocate resources more effectively.
Ensure ethical AI and reduce risks
Metrics can also contribute to ensuring ethical AI practices. By evaluating aspects such as bias, fairness, and transparency in generated content, businesses can address potential ethical concerns and build trust with users. Implementing metrics that track ethical considerations helps in maintaining compliance with regulatory standards and promotes responsible AI usage, ensuring that AI-driven decisions are fair and unbiased. For instance, bias detection metrics can analyze outputs to ensure they are free from discriminatory patterns against any group based on race, gender, or other protected characteristics. Fairness metrics can assess whether the AI’s decisions or generated content are equitable across different demographics. Transparency metrics can evaluate the explainability of AI decisions, ensuring that users and stakeholders understand how and why decisions are made. These efforts not only foster trust but also enhance the overall user experience by providing clear and justifiable AI interactions.
Metrics also play a vital role in compliance and governance by providing measurable standards for evaluating AI models. Regular assessment of compliance metrics ensures that AI systems adhere to industry regulations and internal policies. This systematic evaluation helps mitigate risks associated with non-compliance and enhances the overall governance of AI initiatives, safeguarding the business against potential legal and reputational issues. Moreover, using compliance metrics allows businesses to proactively address regulatory changes and updates, ensuring continuous alignment with legal requirements. This proactive stance can prevent costly fines and sanctions while also demonstrating the company’s commitment to ethical and legal standards.
Governance metrics can also track the consistency and integrity of AI model updates and deployments. By maintaining a clear audit trail of changes and performance over time, businesses can ensure accountability and traceability in their AI practices. This can be crucial in scenarios where decisions made by AI need to be reviewed or challenged, providing a robust framework for defending the fairness and accuracy of AI-driven decisions.
Moreover, the use of generative AI metrics helps in building a robust feedback loop between the AI models and the business processes they support. This feedback loop facilitates the continuous integration of user feedback and performance insights into model updates, leading to iterative improvements that enhance model accuracy and reliability over time. Such a dynamic and responsive system ensures that AI-driven initiatives are aligned with business goals and customer expectations, fostering a culture of excellence and continuous improvement.
Improve the investment
The insights derived from the metrics can inform and identify emerging trends, customer preferences, and potential areas for new product development. This data-driven approach to innovation ensures that the business remains responsive and agile, capable of swiftly adapting to market changes and consumer demands. As a result, companies can introduce groundbreaking solutions that not only enhance customer satisfaction but also open up new revenue streams.
Furthermore, comprehensive AI metrics contribute to better resource allocation and investment decisions. By pinpointing exactly which aspects of the AI models yield the highest returns, businesses can prioritise their investments in areas that promise the greatest impact. This targeted approach to resource management not only maximises the efficiency of AI initiatives but also ensures that budget allocations are strategically aligned with business objectives and market opportunities.
Result: enhance competitive advantage (high level)
In summary, leveraging comprehensive generative AI metrics empowers businesses to maintain a competitive edge in their respective markets through cost reduction, risk mitigation, wise investment, continuous improvement, and informed decision-making. This holistic approach to AI management enables companies to consistently deliver high-quality, innovative solutions that cater to evolving customer needs, ultimately driving long-term success and market leadership.
References
Papers:
Papineni, K., Roukos, S., Ward, T., & Zhu, W.-J. (2002). BLEU: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (pp. 311-318).
Lin, C.-Y. (2004). ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out: Proceedings of the ACL-04 Workshop (pp. 74-81).
Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., & Chen, X. (2016). Improved Techniques for Training GANs. arXiv preprint arXiv:1606.03498.
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners. OpenAI.
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805.
Other sources:
Google AI Blog, KPIs for gen AI: Why measuring your new AI is essential to its success. Nitin Aggarwal, Amy Liu. November 22, 2023. https://cloud.google.com/transform/kpis-for-gen-ai-why-measuring-your-new-ai-is-essential-to-its-success
TensorFlow Extended (TFX) documents:
OpenAI Cookbook Documentation: Getting Started with OpenAI Evals.
OpenAI Documentation: How do I get started doing evals?
Langchain documentation: A guide on using Google Generative AI models with Langchain.
LlamaIndex documentation: Google Generative Language Semantic Retriever.
Appendix
Traditional metrics
Traditional metrics in generative AI play a fundamental role in assessing the quality and performance of AI-generated outputs. These metrics provide quantitative measures that help evaluate various aspects of generated content, such as language fluency, coherence, relevance, and similarity to reference texts. Commonly used traditional metrics include BLEU (Bilingual Evaluation Understudy), ROUGE (Recall-Oriented Understudy for Gisting Evaluation), perplexity, and human evaluation scores.
Perplexity and cross-entropy
Perplexity measures how well a probability distribution or model predicts a sample, with lower values indicating better performance. Cross-entropy quantifies the difference between the predicted probabilities and the true distribution, with lower values suggesting more accurate models.
BLEU and ROUGE Scores
They measure the overlap between the generated text and a reference text. BLEU focuses on the precision of n-grams, while ROUGE emphasises recall. Both metrics provide insights into the similarity and coverage of the generated content.
Human evaluation
Despite advancements in automated metrics, human evaluation remains crucial for assessing generative AI outputs. Human judges can provide nuanced feedback on creativity, coherence, and relevance, which are difficult to capture with automated metrics. However, human evaluation is time-consuming, costly, and subject to variability among evaluators.
Using another model for evaluation
While these traditional metrics offer valuable insights into the effectiveness of generative AI models, they also have limitations, especially in capturing nuanced aspects of language and context. One innovative approach to evaluating generative AI is to use another large model for assessment. For example, an advanced AI model can evaluate the outputs of a generative model by scoring them based on predefined criteria. This method leverages the strengths of powerful models to provide consistent and detailed evaluations.


