In the rapidly evolving landscape of artificial intelligence (AI), the way we store and retrieve data is critical. With the advent of Generative AI (GenAI) technologies, the need for efficient and effective data management systems has never been greater. Among the various database options available, graph databases, such as Neo4j, are emerging as a powerful solution. This blog will delve into what graph databases are, how they compare to traditional vector-based databases, the challenges of implementing them, and their potential for future business applications.
Introduction to graph databases in GenAI
Graph databases are designed to handle and represent complex relationships within data. Unlike traditional relational databases, which organise data into tables, graph databases use nodes, edges, and properties to create flexible and dynamic data models. This structure is particularly advantageous for applications in GenAI, where the relationships between data points are often as important as the data points themselves.
The exploration of graph databases in GenAI offers numerous advantages, including efficient relationship management, flexibility, enhanced performance for complex queries, and advanced analytical capabilities. These benefits make graph databases a powerful tool for businesses looking to leverage the full potential of AI. As the technology continues to evolve, the role of graph databases in enhancing AI applications and driving innovation is likely to grow, providing new opportunities for businesses to gain deeper insights and make more informed decisions.
For instance, Neo4j, one of the leading graph database platforms, allows users to map out intricate networks of information. This capability is vital for AI applications that require understanding and traversing vast amounts of interconnected data, such as natural language processing, recommendation systems, and fraud detection.
However, there are notable challenges and drawbacks to implementing graph databases. Setting up and maintaining these databases requires a deep understanding of the domain and relationships within the data, making the process complex and time-consuming. Scalability remains an issue, particularly for distributed graph databases, and the ecosystem lacks the maturity seen with relational databases. Higher initial costs for specialised software, hardware, and training, alongside potential performance trade-offs in simple transactional operations, also need careful consideration.
How graph databases outperform traditional vector databases
When comparing graph databases to traditional vector databases, several advantages become apparent. For example, in the case of the context of retrieval-augmented generation (RAG) systems:
Relationship mapping
Graph databases excel at managing and querying relationships. In a RAG system, which leverages external knowledge to enhance generative AI models, understanding the relationships between data points can significantly improve the accuracy and relevance of the generated content. This is because graph databases inherently store and traverse data based on connections, allowing for more intuitive and direct queries about how different entities are related. For instance, in a recommendation system, a graph database can quickly identify not just direct connections between users and products but also indirect relationships through shared attributes or behaviours, leading to more nuanced and accurate recommendations.
Flexibility
Graph databases can easily adapt to changes in data structures, making them particularly useful for GenAI applications where data schemas can evolve rapidly. Unlike vector databases, which may require extensive reindexing and restructuring when new types of data or relationships are introduced, graph databases can incorporate new data and relationships seamlessly. This flexibility allows developers to modify and expand their data models without significant downtime or performance degradation. In dynamic environments such as social media analysis or fraud detection, where new patterns and connections constantly emerge, the ability to quickly adapt the database schema is a critical advantage.
Performance
For queries that involve traversing complex relationships, graph databases often outperform vector databases. Operations that would be computationally expensive in a vector database, such as multi-hop queries or deep link analysis, can be executed more efficiently in a graph database due to its inherent structure. Graph databases are designed to handle these types of queries naturally, using optimised algorithms for graph traversal. This means that applications requiring complex relationship analysis – such as identifying influencers in a social network or tracking supply chain dependencies – can achieve better performance and scalability with a graph database. Additionally, graph databases can handle large volumes of connected data more efficiently, reducing the time and resources needed for processing and analysis.
Overall, the inherent strengths of graph databases in managing relationships, their flexibility in adapting to new data structures, and their superior performance in handling complex queries make them a powerful alternative to traditional vector databases in RAG systems and beyond.
Challenges in implementing graph databases
Despite their advantages, there are several challenges associated with implementing graph databases:
Complexity of setup
Building a graph database requires a thorough understanding of the data and its interrelationships. Unlike relational databases, where data is organised into predefined tables, graph databases rely on nodes and edges to represent entities and their connections. This necessitates a meticulous approach to setting up the database schema. Identifying the right entities (nodes), defining their properties, and establishing the relationships (edges) between them can be a complex and time-consuming process. Incorrect or incomplete modelling can lead to inefficient queries and poor database performance, which underscores the importance of domain expertise and detailed planning during the setup phase.
Cost
The initial cost of setting up a graph database can be higher compared to traditional relational databases. This includes not only the financial investment in specialised software and hardware but also the significant time and resources needed for training and development. Implementing a graph database often requires hiring or upskilling staff to ensure they have the necessary knowledge and expertise to manage and optimise the database effectively. Additionally, the ongoing maintenance and support of a graph database can incur higher operational costs, as it may involve dealing with complex performance tuning and scaling challenges.
Performance concerns
While graph databases excel in handling complex relationship queries, they may not perform as well as relational databases in certain scenarios, particularly those involving simple transactional operations. Relational databases are highly optimised for ACID (Atomicity, Consistency, Isolation, Durability) transactions, which are essential for ensuring data integrity and reliability in many business applications. In contrast, graph databases may not offer the same level of performance for these types of operations due to their focus on relationship-centric queries. This necessitates a careful consideration of the specific use cases to determine whether a graph database is the right fit. For applications that require a mix of transactional and complex relationship queries, a hybrid approach or a detailed evaluation of performance trade-offs might be necessary.
Data migration and integration
Migrating data from traditional relational databases to graph databases can be a challenging task. This process involves transforming the data model and potentially rewriting large parts of the application to take advantage of the graph database’s features. Ensuring data consistency and integrity during this migration is critical and can be complex, particularly for large datasets or systems with high transaction volumes. Furthermore, integrating a graph database with existing systems and workflows may require custom development efforts and a thorough understanding of both the existing architecture and the new graph database technology.
Scalability issues
While graph databases handle large and complex datasets well, they can face challenges when scaling horizontally. Managing distributed graph databases efficiently is still an area of active research and development. Ensuring consistent performance and data integrity across distributed nodes can be difficult, and solutions like sharding, which are commonly used in relational databases, do not always translate seamlessly to graph databases. This means that organisations may need to invest in specialised solutions or architectures to achieve the desired scalability and performance.
Implementation
Implementing graph databases presents several challenges, including the complexity of setup, higher initial and operational costs, performance trade-offs, data migration and integration difficulties, and scalability issues. However, the advantages of graph databases may outweigh these challenges. Careful planning, a thorough understanding of the use case, and investment in the necessary expertise and resources are crucial for successfully leveraging the power of graph databases.
In this example, we’ll demonstrate how to use Llama Index and Neo4j to build a graph database RAG (Retrieve and Generate) pipeline.
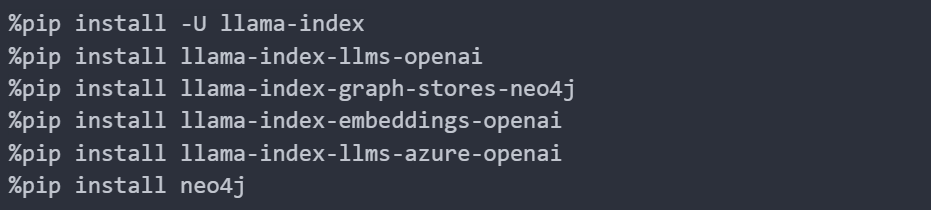
Install the packages:
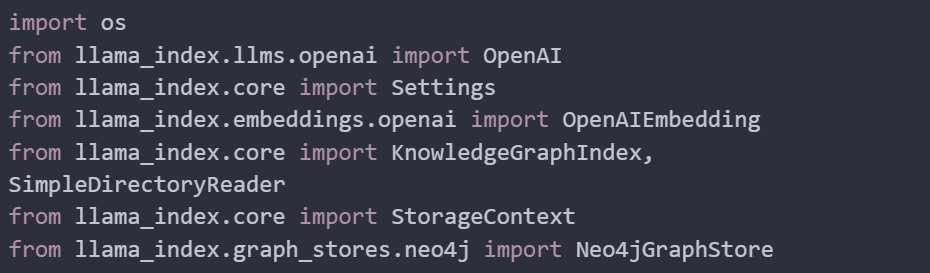
Now we are importing the installed package to set up an environment to work with Llama Index, a library for building and querying knowledge graphs. We’re integrating it with OpenAI’s powerful language models and embeddings and using Neo4j as our graph database:
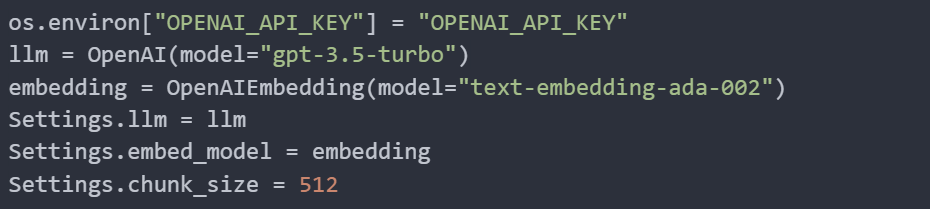
First, we set the OpenAI API key in the environment variables. Next, we initialise the OpenAI language model (gpt-3.5-turbo) and the embedding model (text-embedding-ada-002). We then configure the global settings for Llama Index to use these models:
First, we create a directory called data/paul_graham/ to store our text files. Next, we download three copies of an essay by Paul Graham from the Llama Index GitHub repository:

First, we load the documents from the directory we prepared earlier:

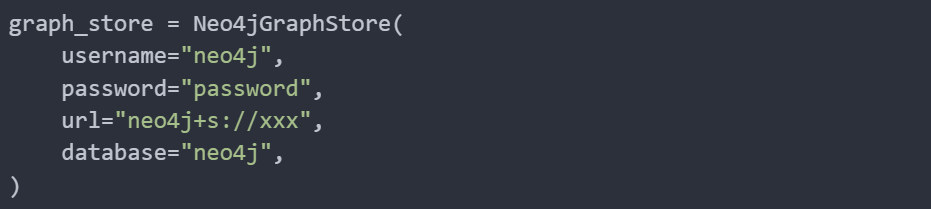
Next, we set up the Neo4j graph store:
We then create a storage context using the graph store:

Finally, we build the knowledge graph index from the loaded documents. This creates an index from our documents, storing the data in the Neo4j graph store. The max_triplets_per_chunk parameter controls how many triplets (subject-predicate-object statements) are generated per chunk of text, limiting it to 2 in this case:

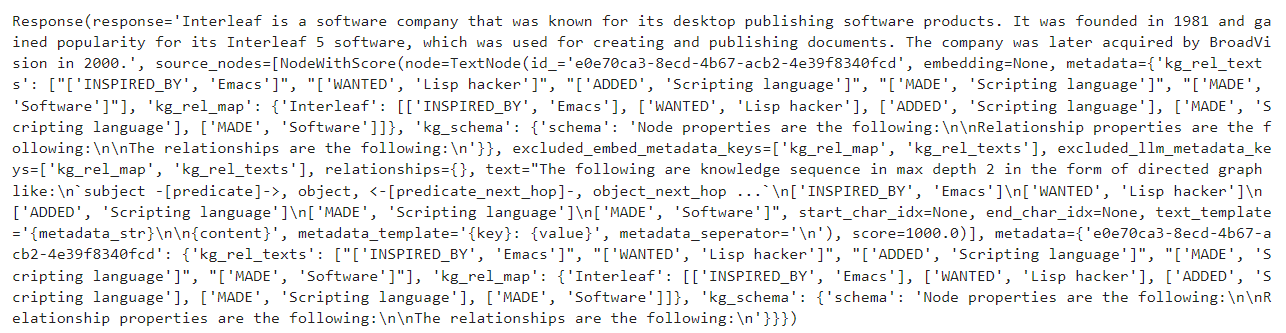
Now we configure the query engine and let it retrieve the information to answer the query ‘What is Interleaf?’

Further improvement: potential business context
The potential for graph databases in business contexts is vast. Here are a few areas where they can be particularly transformative:
Customer Relationship Management (CRM)
Graph databases can revolutionise Customer Relationship Management (CRM) by mapping out relationships between customers, products, and interactions. Traditional CRM systems often struggle to provide a comprehensive view of customer relationships due to their reliance on tabular data structures. In contrast, graph databases excel at visualising complex relationships, allowing businesses to gain deeper insights into customer behaviour and preferences. By understanding how customers are connected through shared interests, purchase history, and social interactions, businesses can enhance their engagement strategies and foster stronger customer loyalty.
Supply chain management
In supply chain management, graph databases can play a crucial role in visualising and optimising complex supply chains. Graph databases allow for the modelling of supply chain networks as interconnected nodes and edges, representing suppliers, products, transportation routes, and delivery schedules. This holistic view helps identify bottlenecks, optimise routes, and improve inventory management. Additionally, graph databases can facilitate real-time monitoring and predictive analytics, enabling businesses to respond quickly to disruptions and ensure a more resilient supply chain.
Fraud detection
Fraud detection in finance is another area where graph databases can be transformative. Traditional databases may miss intricate patterns of fraudulent activity due to their inability to efficiently analyse complex relationships. Graph databases, however, can uncover hidden connections and suspicious patterns by analysing the web of transactions, accounts, and entities involved in financial activities. This capability allows for more effective detection of money laundering, identity theft, and other fraudulent schemes.
Social network analysis
Understanding user interactions, identifying influencers, and tracking the spread of information is critical for managing social platforms. Graph databases can analyse the complex web of user connections, helping to identify key influencers who drive trends and opinions. They also enable the tracking of information dissemination, allowing platforms to understand how content spreads and which users are most influential in the process. This insight can inform content strategy, advertising, and community management, leading to more effective engagement and growth.
Healthcare and biomedical research
In healthcare, graph databases can be used to model relationships between patients, treatments, medical conditions, and healthcare providers. This can lead to better patient care through personalised treatment plans and more effective disease management. Additionally, in biomedical research, graph databases can help in understanding complex biological networks, such as gene interactions and protein pathways.
Knowledge management and recommendation systems
Graph databases can enhance knowledge management by organising and connecting vast amounts of information. Businesses can create knowledge graphs that link documents, research, and data points, making it easier to retrieve relevant information and derive insights. Similarly, in recommendation systems, graph databases can analyse user preferences and item similarities to provide more accurate and personalised recommendations.
Conclusion
Graph databases represent a significant advancement in the field of data management, particularly suited for the nuanced requirements of Generative AI systems. While they present certain challenges, their ability to efficiently manage complex relationships and adapt to evolving data makes them a valuable tool in various business applications. As AI continues to evolve, the role of graph databases is likely to expand, offering new opportunities for businesses to leverage their data more effectively. Embracing this technology could be the key to unlocking the full potential of GenAI and driving innovation across industries.
References
Robinson, I., Webber, J., & Eifrem, E. (2015). Graph Databases: New Opportunities for Connected Data. O’Reilly Media.
van Bruggen, D. (2020). “Graph Databases vs. Relational Databases: A Comparison”. Towards Data Science.
Needham, M., & Hodler, A. (2019). Graph Algorithms: Practical Examples in Apache Spark and Neo4j. O’Reilly Media.
Batra, S., & Tyagi, C. (2012). “Comparative Analysis of Relational and Graph Databases”. International Journal of Soft Computing and Engineering (IJSCE), 2(2), 509-512.
Pötsch, M. (2017). Performance Optimization of Graph Databases. Technical University of Munich.
Webber, J. (2023). How knowledge graphs improve generative AI. Infoworld: Generative AI Insights. https://www.infoworld.com/article/3707814/how-knowledge-graphs-improve-generative-ai.html
Goasduff, L. (2021). Gartner Identifies Top 10 Data and Analytics Technology Trends for 2021. Gartner. https://www.gartner.com/en/newsroom/press-releases/2021-03-16-gartner-identifies-top-10-data-and-analytics-technologies-trends-for-2021
Natarajan, M. (2022). The Future of AI: Machine Learning and Knowledge Graphs. Neo4j Blog. https://neo4j.com/blog/future-ai-machine-learning-knowledge-graphs/


