This article explores the development of a local Retrieval-Augmented Generation (RAG) system using Google’s Gemma Large Language Model (LLM) and AlloyDB, a managed PostgreSQL-compatible database service. This system aims to address the growing demand for efficient and contextually-aware Question Answering (Q&A) applications.
Retrieval-Augmented Generation (RAG)
Traditional information retrieval techniques often rely on keyword matching, which can be ineffective due to the inherent ambiguity and complexity of natural language. RAG addresses this limitation by combining retrieval and generation techniques. In the retrieval stage, relevant information is retrieved from a knowledge base based on the user’s query. Subsequently, the generation stage leverages a large language model to create a comprehensive and informative answer that incorporates the retrieved information (Wu et al., 2019).
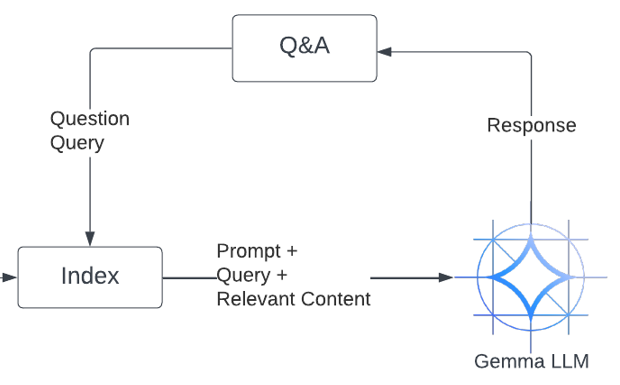
System architecture
Components
- AlloyDB: This serves as the system’s knowledge base. It stores reference text documents, their corresponding text embedding vectors, and facilitates real-time querying for relevant content based on user queries.
- Gemma LLM: This lightweight open-source LLM acts as the core component for answer generation. It processes the user’s query, retrieves information from AlloyDB, and a designed prompt to generate an accurate and well-structured answer.
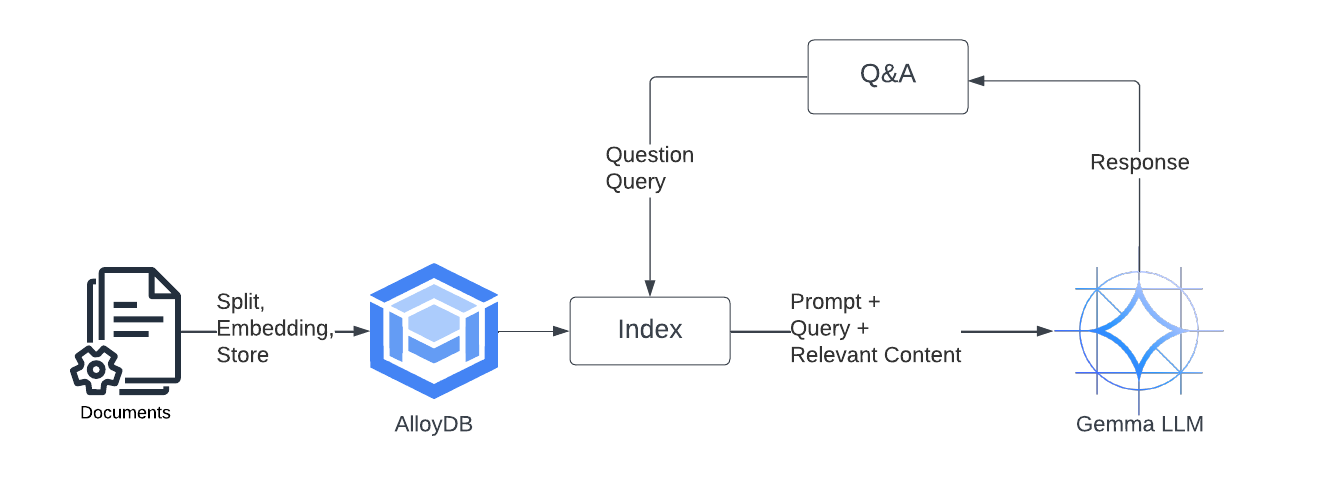
Process flow
- Data preprocessing: Reference text documents are preprocessed, which involves splitting the documents into smaller chunks and generating text embeddings for each chunk. Text embeddings are vector representations that capture the semantic meaning of the text. This step facilitates efficient retrieval of relevant information during the query processing stage.
- Knowledge base population: The preprocessed documents and their corresponding text embeddings are stored within AlloyDB.
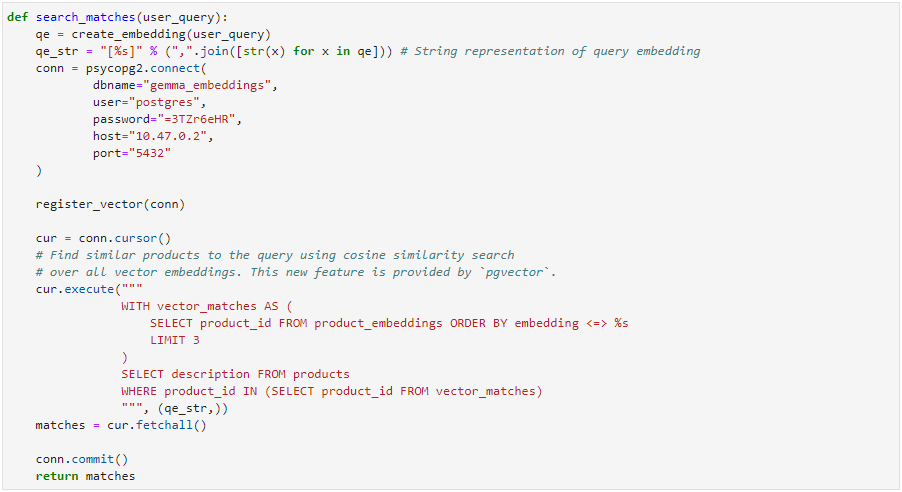
- User query processing: Upon receiving a user query, the system retrieves relevant document chunks from AlloyDB using a vector similarity search based on the query embedding.
- Answer generation: Gemma LLM takes the user query, retrieved document chunks, and a predefined prompt as input. It then generates a human-quality answer that incorporates the retrieved information and addresses the user’s intent.

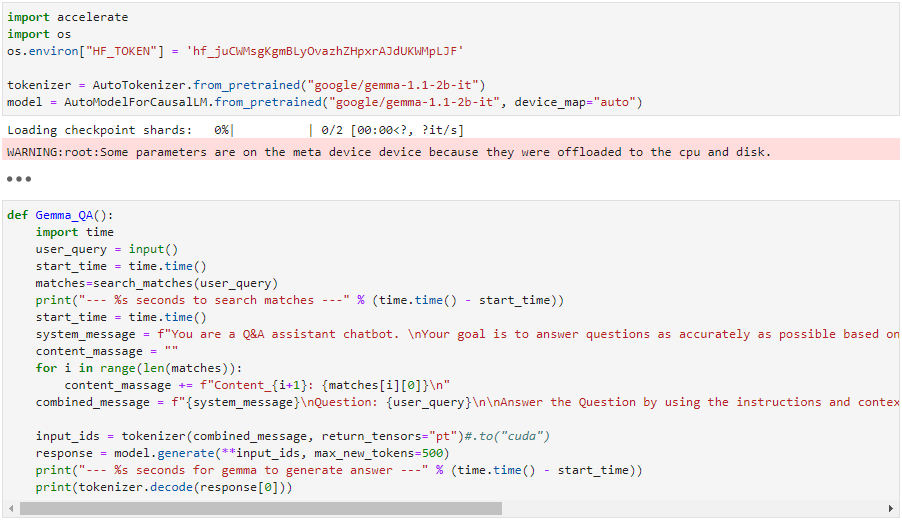
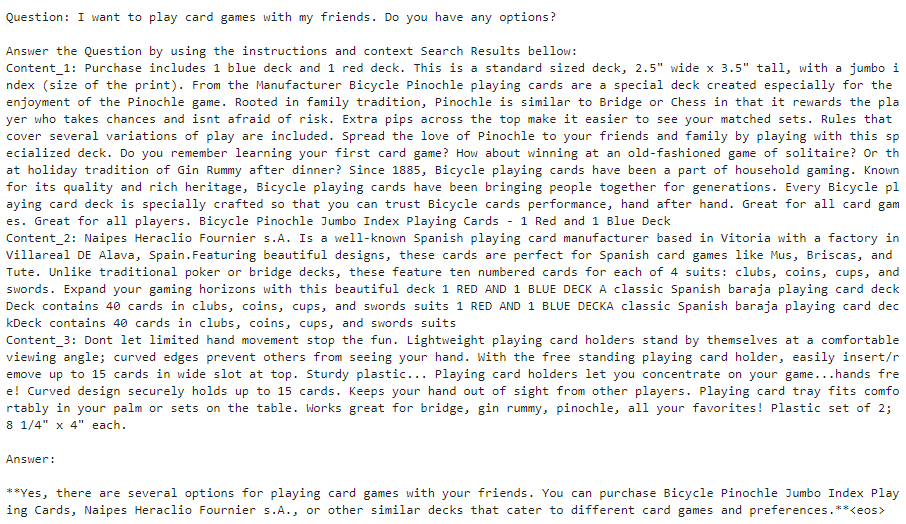
Implementation considerations and challenges
1. Environment setup
- Dependency management:
- Careful consideration is required regarding the compatibility of libraries and frameworks used across different components.
- Version control tools like pipenv or conda can ensure consistent dependency versions.
- Network configuration:
- Proper Virtual Private Cloud (VPC) network configuration is crucial to enable communication between the Python script running locally and the AlloyDB instance.
2. Data management
- Text embedding selection:
- The chosen text embedding model needs to generate vectors dimensionality compatible with AlloyDB’s indexing limitations (e.g., below 2,000 dimensions). OpenAI’s ‘text-embedding-ada-002’ model (1,536 dimensions) is a suitable choice in this scenario.
- Data splitting and storage:
- Splitting the text into chunks for embedding generation offers several advantages:
- Enables efficient retrieval of relevant information during the query processing stage.
- Reduces the overall database write size and query processing time.
- Two separate tables in AlloyDB can store text chunks and their corresponding embeddings, along with any associated metadata (e.g., document ID). This approach avoids data overwriting issues when modifying the chunking or embedding methods.
- Splitting the text into chunks for embedding generation offers several advantages:
3. Performance optimisation
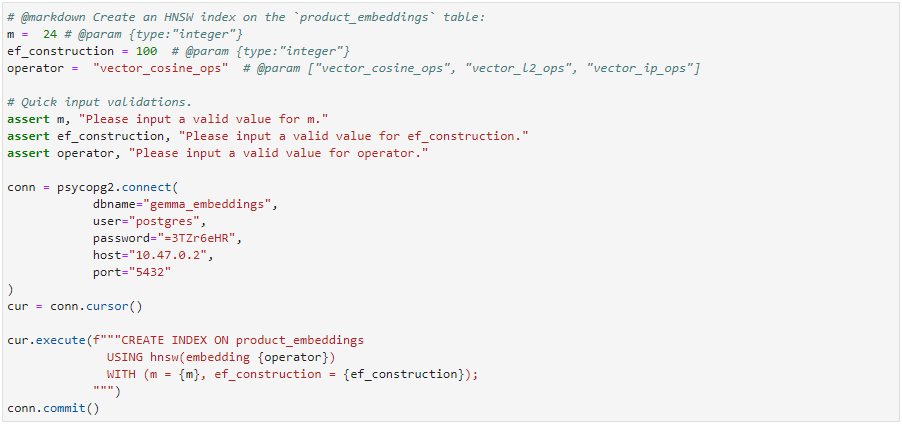
- Indexing:
- Creating an index on the embedding table within AlloyDB can significantly improve the performance of similarity search operations. Hierarchical Navigable Small World (HNSW) indexes offer a good balance between search speed and accuracy for this application.
- Hardware acceleration (optional):
- A Graphics Processing Unit (GPU) can potentially accelerate the LLM inference process, thus reducing Gemma’s response time. However, leveraging the GPU for LLM computations may require additional hardware resources and code modifications.
Conclusion
The proposed local RAG system demonstrates the feasibility of leveraging Gemma LLM and AlloyDB for building an efficient Q&A system. While the current implementation yields promising results, further exploration can enhance its capabilities.
- Text chunking strategies: Exploring different text chunking strategies could potentially improve the relevance and quality of retrieved information.
- LLM selection: Investigating more powerful LLMs, potentially in conjunction with hardware acceleration, could lead to the generation of even more comprehensive and informative answers.
- Error handling and logging: Implementing robust error handling mechanisms and detailed logging can facilitate troubleshooting and system improvement.
The development of this local RAG system paves the way for further research into building scalable and contextually-aware Q&A applications using Google’s advanced language.


