Introduction
Large language models (LLMs) are powerful but fixed; they cannot change their weights for new tasks, knowledge, or examples. We introduce Self-Adapting LLMs (SEAL), a framework that lets LLMs adjust by creating their own finetuning data and update steps. When given new input, the model makes a self-edit — this may restructure the information, set training settings, or call tools for extra data. Through supervised finetuning (SFT), these edits update the model’s weights and keep the changes. To train the model to make better edits, we use reinforcement learning, where the model’s improved performance is the reward. Unlike older methods that rely on extra modules, SEAL uses the model’s own outputs to guide and control its updates. Tests on knowledge use and few-shot learning show SEAL is a good step toward models that adapt by themselves.

Method

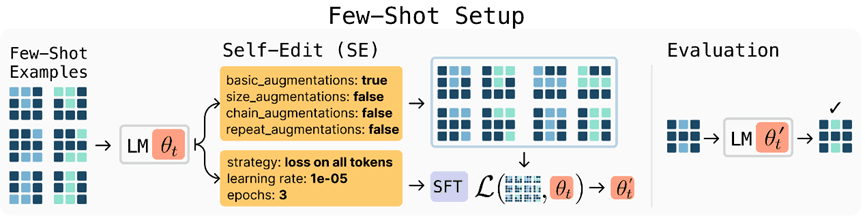
Overview of SEAL. In each RL outer loop iteration, the model generates candidate self-edits (SE) directives on how to update the weights, applies corresponding updates, evaluates performance on a downstream task, and uses the resulting rewards to improve the self-edit generation policy.
SEAL is a framework that enables language models to generate their own finetuning data and optimization instructions—called self-edits—in response to new tasks or information. SEAL learns to generate these self-edits via reinforcement learning (RL), using downstream task performance after a model update as the reward. Each training iteration involves the model generating a self-edit based on a task context, applying the self-edit via supervised finetuning, evaluating the updated model, and reinforcing edits that improve performance. This process is implemented with a lightweight reinforcement learning algorithm called ReSTEM, which does rounds of selecting high-reward samples using rejection sampling and reinforcing via SFT. We demonstrate SEAL in two domains:
- Knowledge Incorporation, where the model integrates new factual information by generating logical implications as synthetic data, and
- Few-Shot Learning, where the model autonomously selects data augmentations and training hyperparameters to adapt to new abstract reasoning tasks.

SEAL Reinforcement Learning Loop. The specific format of the self-edits (SE) is defined per task domain.
Experiments
We test SEAL on two domains:
Knowledge incorporation, where the task is to finetune the model to internalize new factual information from a given passage such that it can answer related questions without access to the original context.

Few-shot learning on ARC, where the model must generalize from a small number of demonstrations by generating its own data augmentations and training configurations to solve abstract reasoning tasks. Here are visuals of both setups.
Results
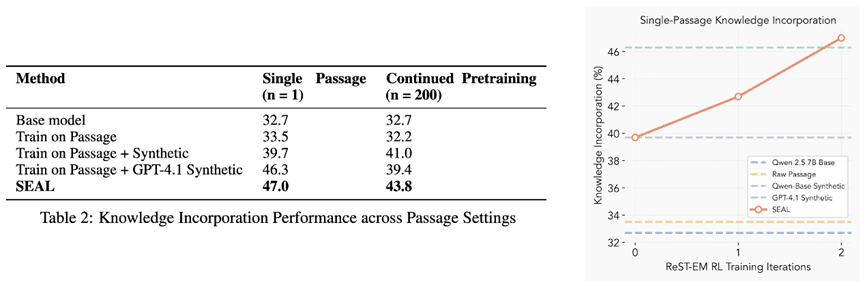
Knowledge Incorporation: On a single passage, SEAL raises QA accuracy from 32.7% (no change) to 47.0% after two ReST-EM rounds. This is better than models trained on raw passages or GPT-4.1 made data. With 200 passages, SEAL again performs best at 43.8%, showing it can scale. These results show SEAL can turn plain text into training data that gives lasting knowledge.
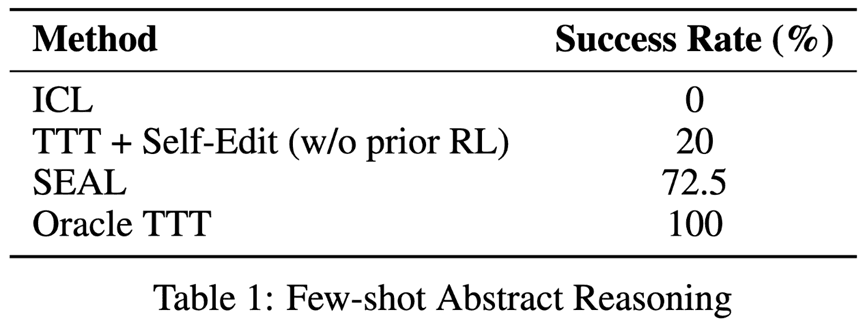
Few-Shot Learning: On a small ARC test, SEAL reaches 72.5% success, better than in-context learning (0%) and test-time training with no trained edits (20%). This shows SEAL can choose useful training strategies and generalize from a few examples.
Limitations
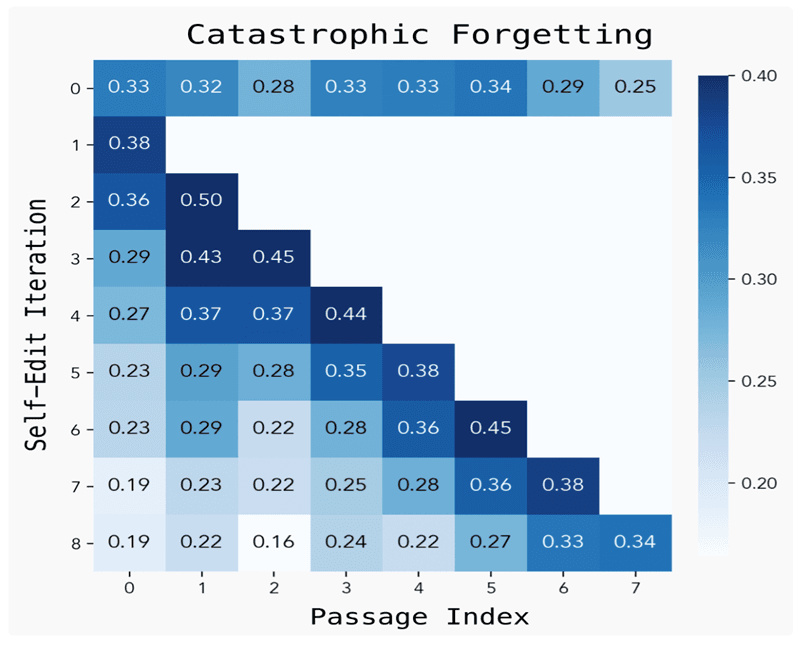
SEAL allows lasting updates, but long use shows a problem: repeated edits can cause the model to forget earlier tasks (catastrophic forgetting). Without special memory, self-changes can overwrite old knowledge. Fixing this is still open, with ideas like replay, limited updates, or layered memory as possible ways forward.
Future Work
Next, we see models that not only update but also decide when to update. They may choose mid-task whether to make an edit. They could also turn step-by-step thoughts into permanent weights, making reasoning last. This can help build agent models that continually improve through work and reflection.

