What is Chunking?
Nowadays, the development of large language models (LLMs) is progressing rapidly. However, with their advancements come certain drawbacks, such as hallucinations. To address this issue, Retrieval-Augmented Generation (RAG) was developed. Let’s briefly introduce RAG. RAG is a natural language processing technology that combines retrieval and generation. It operates through the following steps:
- Retrieval: Extracting the most relevant text fragments from a large database or document collection based on the user’s query.
- Generation: Using a generative model (such as GPT) to produce more detailed and accurate responses based on the retrieved text fragments.
One of the most critical aspects of RAG is the preparation of text fragments. Instead of feeding an entire book to a generative model (which is currently impractical), we use a process called chunking. Chunking involves dividing large volumes of text into manageable blocks and encoding these blocks into high-dimensional vector embeddings. These embeddings are then stored in a vector database. During the retrieval phase of the RAG pipeline, distance algorithms are used to find the text blocks that are most relevant to the user’s query. This is the basic concept of chunking.
Why do we need Chunking?
As the volume of information contained in large documents continues to grow, the challenge of efficiently and accurately retrieving relevant data becomes increasingly complex. This is where chunking plays a pivotal role in the RAG process. By breaking down extensive texts into smaller, more manageable segments, chunking enhances the performance and accuracy of information retrieval and generation. Here are four key benefits of chunking:
- Relevance: Chunking helps in breaking down large documents into smaller, more manageable pieces. This increases the likelihood of retrieving the most relevant chunks that directly address the user’s query, thereby improving the accuracy of the information retrieval process.
- Context preservation: By using appropriately sized chunks, RAG models can maintain contextual coherence within each chunk. This ensures that the generated responses are contextually accurate and relevant.
- Segmentation: Long documents can be overwhelming for RAG models. Chunking breaks them into digestible parts, making it easier for the model to handle and process each segment effectively.
- Coverage: It ensures that various parts of a long document are considered, increasing the chances of retrieving diverse and comprehensive information relevant to the user’s query.
Some popular chunking strategies
Fixed-length text splitter
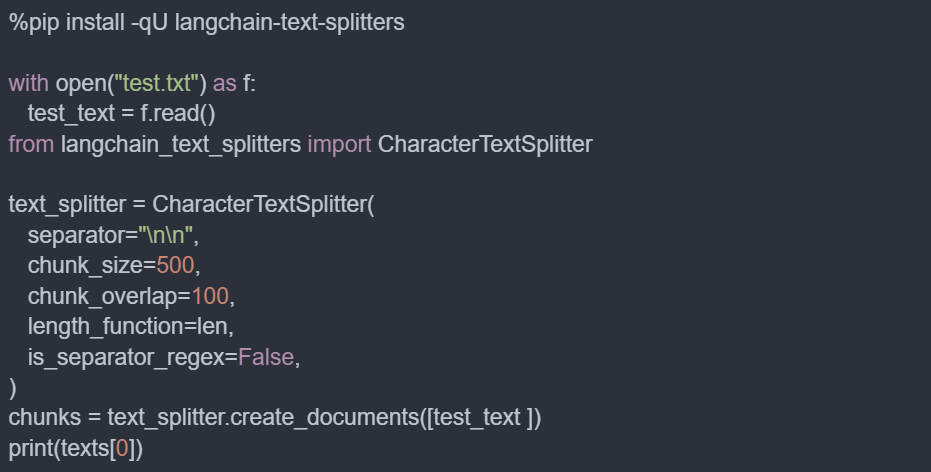
A fixed-length text splitter divides the text into chunks of a predetermined fixed length, such as a specific number of words or characters. This method is straightforward and ensures uniformity in chunk size, which can simplify the retrieval process. However, it might occasionally split sentences or paragraphs in ways that disrupt the flow of information.
Implementation
Semantic text splitter
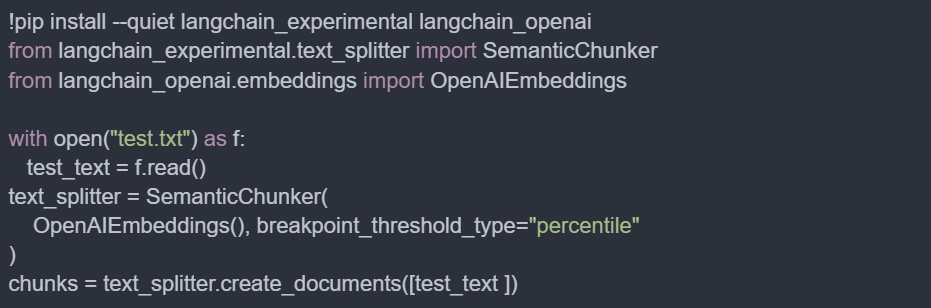
Unlike the fixed-length approach, semantic text splitting divides text based on its meaning and natural boundaries, such as sentences, paragraphs, or semantic units. This method preserves the contextual integrity of each chunk, making it easier for the generative model to understand and generate accurate responses.
A quick summary of how semantic text splitter works on a sentence level
Initial embedding and comparison:
- Start with the first sentence and obtain its embedding.
- Compare this embedding with the embedding of the second sentence.
- Continue comparing subsequent sentences to find ‘break points’ where the embedding distance is significantly large.
Identifying break points:
- If the embedding distance between sentences exceeds a certain threshold, mark this as the beginning of a new semantic section.
Windowed approach for smoother results:
- Instead of taking embeddings of every individual sentence, use a sliding window approach.
- Group sentences in windows of three.
- Obtain the embedding for this group.
- Drop the first sentence of the group, add the next sentence, and continue the process.
Implementation
Parent Document retriever
Parent Document retriever is more advanced than the above two methods, it introduced a parent-child hierarchy in chunks. So, why does this hierarchy make this method advantageous in RAG and improve the accuracy of retrievals? Actually, it resolves the problems of conflicting goals when splitting documents for retrieval.
- You may want to create small chunks so their embeddings can most accurately reflect their meaning. If the documents are too long, the embeddings can lose their meaning.
- You also want the documents to be long enough to retain the context of each chunk.
Parents refer to the larger chunks, while children are the smaller chunks derived from these parent chunks. This method strikes a balance by splitting and storing small chunks of data. During retrieval, it first fetches these child chunks but then looks up the parent IDs for those children and returns the larger chunks.
Implementation
Install all involved LangChain packages.
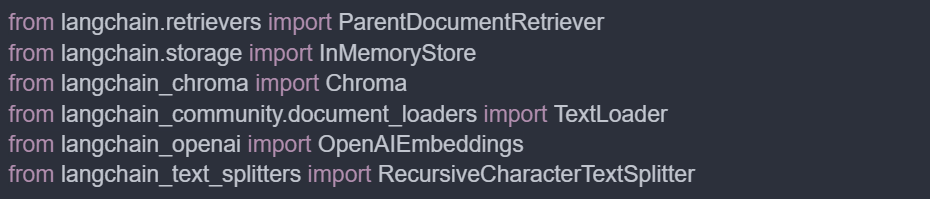
Set up LangChain loaders and load the documents.

Now we need two splitters: one for the larger chunks that provide more context (parent chunks) and another for the smaller chunks that offer better semantic clarity (child chunks).
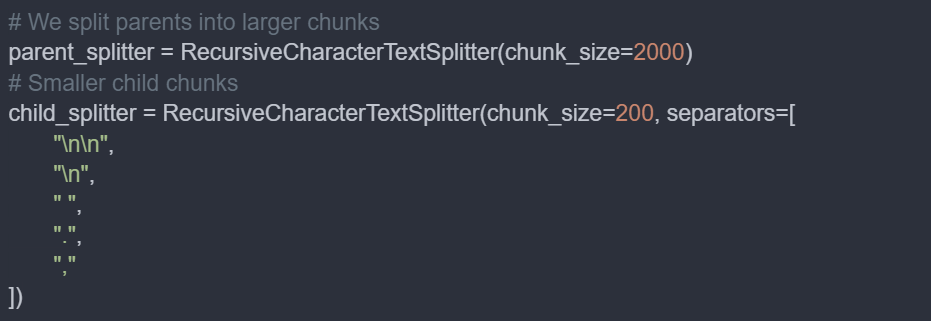
Now, we will create the vector store and InMemoryStore.
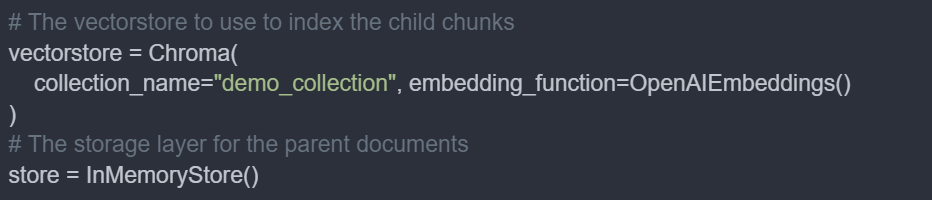
The first line of code creates a vector store using Chroma, optimised for storing and querying embeddings.
store initialises an in-memory key-value store.
These two storage systems work in tandem to manage different aspects of the text data:
Vector Store (Chroma):
- Purpose: Stores embeddings of smaller text chunks
- Contents: Vector representations of text, along with metadata
- Key feature: Each embedding includes metadata containing the UUID of its parent large chunk
- Advantage: Enables efficient semantic search on smaller text units
InMemoryStore:
- Purpose: Holds larger text chunks in their original form
- Structure: Key-value pairs
- Key: A unique UUID for each large chunk
- Value: The full-text content of the corresponding large chunk
- Advantage: Provides quick access to complete context when needed
This dual-storage approach allows for:
- Precise semantic searching using the vector store’s embeddings of smaller chunks
- Easy retrieval of full context by using the UUID to fetch the original large chunk from the InMemoryStore
Now, let’s create a parent document retriever.
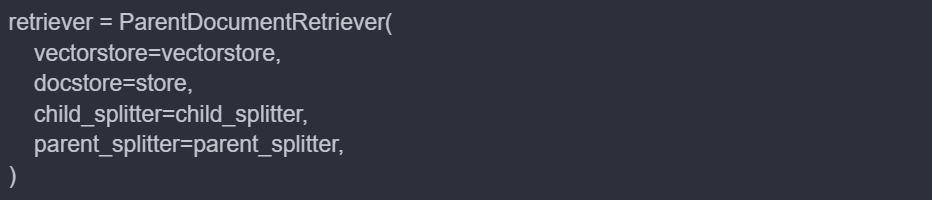
The ParentDocumentRetriever is initialised with four key components:
- vectorstore:
- Purpose: Stores embeddings of child chunks
- Type: A vector database (in this case, Chroma)
- Function: Enables semantic search on these smaller text units
- docstore:
- Purpose: Houses parent chunks
- Type: An in-memory key-value store (InMemoryStore)
- Structure: Keys are unique UUIDs, values are full-text content
- child_splitter:
- Purpose: Divides parent chunks into smaller chunks
- Function: Creates fragments suitable for embedding and semantic search
- parent_splitter:
- Purpose: Divides docs into larger chunks
- Function: Produces sizeable text units that maintain a broader context
Then, we can add the documents to the retriever, and it would execute the following steps:
- A unique identifier (UUID) is created.
- The parent chunk is stored in the docstore.
- The UUID serves as the key, and the parent chunk’s full text is the value.
- The parent chunk is subdivided into child chunks using the child_splitter.
- Each child chunk is embedded and added to the vectorstore.
- Metadata is attached, including the parent_id set to the UUID of the originating large chunk.

Finally, you can retrieve either parent or child chunks based on your specific needs.
Conclusion
Chunking is a crucial process in Retrieval-Augmented Generation (RAG) systems, addressing the challenges posed by large volumes of text data. By dividing extensive documents into manageable segments, chunking enhances the efficiency and accuracy of information retrieval and generation.
We’ve explored three key chunking strategies: the straightforward fixed-length text splitter, the context-preserving semantic text splitter, and the advanced Parent Document retriever. Each method offers unique advantages, from simple implementation to maintaining semantic coherence and balancing granularity with context preservation.
The Parent Document retriever, in particular, stands out for its ability to create a hierarchy of chunks, allowing for both precise semantic search and comprehensive context retrieval. As RAG systems continue to evolve, effective chunking remains essential in bridging the gap between vast information sources and accurate, context-aware language generation. By carefully selecting and implementing the appropriate chunking strategy, You can significantly improve the performance and relevance of RAG applications, ultimately leading to more intelligent and responsive AI-powered information systems.


